
斯坦福HAI的《2025年人工智能指数报告》洋洋洒洒456页,其中最吸睛的莫过于AI在各类基准测试中的“优异”表现。MMMU提升18.8%,GPQA提升48.9%,SWE-bench更是夸张地提升了67.3%。乍一看,AI简直要统治世界了!但冷静下来想想,这些基准测试真的能反映AI的真实能力吗?
MMMU,号称评估大学水平的多学科理解能力,听起来很高大上,但仔细分析,它仍然是一个封闭的测试集。而任何针对特定数据集的优化,都可能导致模型在测试中取得高分,但在真实世界中却表现平平。这就像是学生为了考试疯狂刷题,结果考场上遇到稍微变形的题目就傻眼。
GPQA,由领域专家编写的高质量难题,专家正确率也只有65%。这难道不是暴露了专家们自身的局限性吗?让AI来挑战人类专家的难题,本身就是一个有争议的设定。更何况,AI可以调用海量数据,进行穷举式的搜索和推理,这对于人类来说是不可能做到的。这种比较,公平吗?
SWE-bench,评估AI在软件问题上的表现。代码生成能力的确是AI的一个重要应用方向,但报告中提到“大型语言模型甚至在限时编程任务中超越了人类”,这种说法有误导性。人类程序员不仅要写代码,还要进行需求分析、系统设计、代码调试等等。AI在短期内能够替代的,仅仅是coder这个角色,而非真正的程序员。
所以,对于这些基准测试的结果,我们不能盲目乐观。它们或许反映了AI在某些特定领域的进步,但并不能代表AI的整体能力。更重要的是,我们需要思考这些基准测试的意义,以及如何设计更科学、更全面的评估体系,才能真正了解AI的现状和未来。


AI工廠電力革命:維諦搶先布局800VDC迎戰NVIDIA,劉揚偉怎麼看?
2025-05-22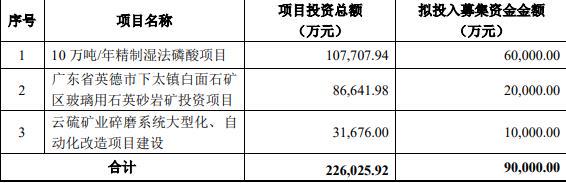
粤桂股份9亿定增豪赌?仁宝股價疲软下,豪赌磷酸与主权基金风险
2025-05-22

